
Google Releases Cloud Text-to-Speech Tool For Developer

Text-to-speech synthesis has made great strides over the course of the last few years, up to the point where many modern systems almost sound like a real person is reading a text. Google has been among the leaders of this development and starting today, developers will get access to the same DeepMind-developed text-to-speech engine that the company itself is current using for its Assistant and for its Google Maps direction.
In total, Cloud Text-to-Speech features 32 different voices from 12 languages and variants. Developers will be able to customize the pitch, speaking rate and volume gain of the MP3 or WAV files the service will generate.
Not all the voices are created equal, though. That’s because the new service also features six English language voices that were all built using WaveNet, DeepMind’s model for creating raw audio from text.
Unlike previous efforts, WaveNet doesn’t do speech synthesis based on a collection of short speech fragments, which tends to create the kind of robotic sounding voices you are surely familiar with. Instead, WaveNet models raw audio using a machine-learning model to create a far more natural-sounding speech. Google says that in its test, people rated these WaveNet voices over 20 percent better than standard voices.
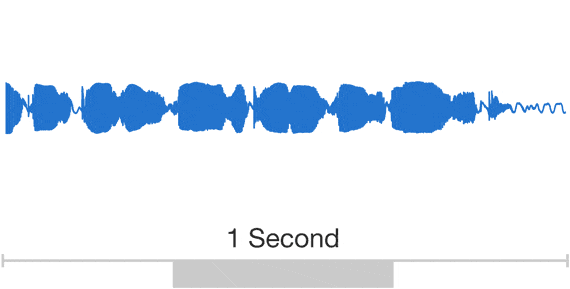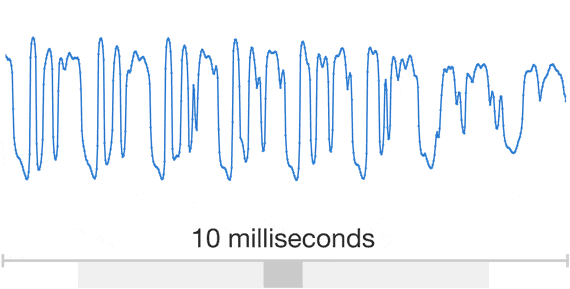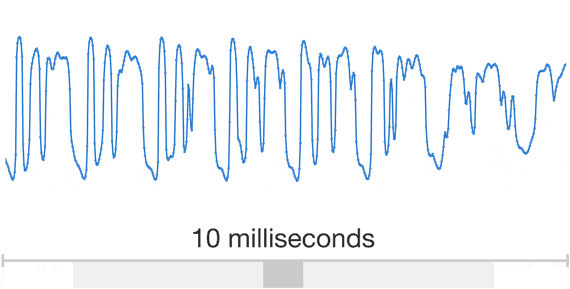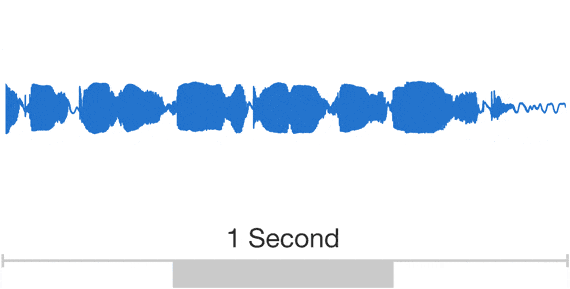
Google first talked about WaveNet about a year ago. Since then, it moved these tools to a new infrastructure that sits on top of the company’s own Tensor Processing Units. This allows it to generate these audio waveforms 1,000 times faster than before, so generating a second of audio now only takes 50 milliseconds.